

Graduate Researcher:
Yunjian (Jojo) Qiu
Wei Suo
Faculty Adviser:
Prof. Yan Jin
In the engineering design domain, it is valuable to identify and applied the useful information or rules from the past documents like design reports or papers. To use the unstructured text for design knowledge acquisition, researchers have focused more on word embeddings for design creativity inspiration or rule generation. However, text understanding at the sentence level has rarely been used for knowledge acquisition due to the lack of benchmark datasets, poor training performance of models and high computational burden. In addition, it is worth mentioning that text understanding is the principal step for people to cooperate with computers effectively in the future. Therefore, there is a strong need for devising ways to train the computer to read and understand the unstructured texts and generate its “understanding” in the format that can quickly and effectively help human designers grasp the key knowledge.
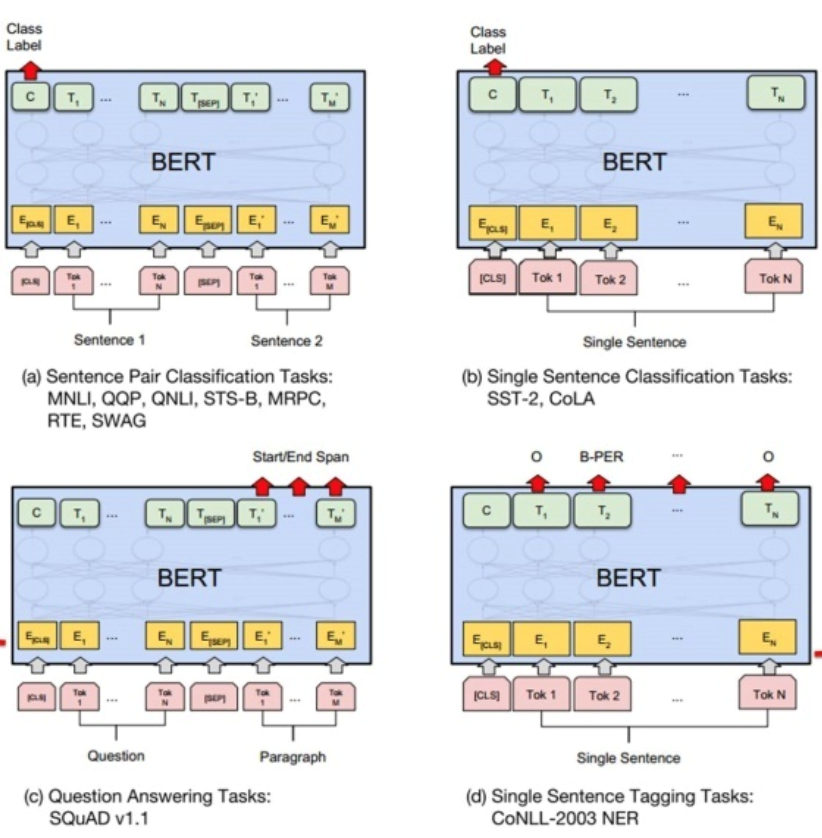
In this study, a systematic approach is taken to investigate the training process of the models learning specific domain knowledge from different datasets. The results produced by the trained models are analyzed and evaluated. Specifically, a manually labeled dataset is created and used to train a BERT based language model. In addition, using the K-Means method, the sentence embeddings extracted from the BERT model are clustered and the centroids of each cluster are selected and included in the final summarization. During this process, the BERT models can learn to select significant sentences in the papers to represent their main ideas. Since the BERT model can only deal with classification problems, the extractive summarization is considered as a binary classification problem where the labels, i.e., 1 and 0, are used to indicate whether a sentence should be included in the summary or not. To make the model generate summaries, sentence embedding will be extracted from the BERT model and then the K-Means method is used to deal with the clustering which is formed by those sentence embeddings. Finally, the centroid of each cluster will be selected and combined to complete a summary. Here the number of clusters will represent the number of sentences included in the summary. In this way, computers can acquire the understanding ability from the BERT model by sentence embeddings and output corresponding summarization using the K-Means method.